


MapReduce是一种强大的编程模型,用于处理大规模数据集,特别适用于并行处理多个CSV文件。从入门到实践,用户需掌握其基本原理,即将复杂任务分解为“Map(映射)”和“Reduce(归约)”两个简单步骤。Map阶段处理输入数据(如CSV文件中的行),产生中间键值对;Reduce阶段则合并这些键值对,输出最终结果。通过实践,用户能高效处理海量CSV数据,实现数据清洗、分析等功能,提升数据处理效率与准确性。
一文了解“如何实现MapReduce处理多个CSV文件的输入?”
在大数据处理领域,MapReduce作为一种强大的并行计算模型,广泛应用于处理海量数据,当面对多个CSV(逗号分隔值)文件时,MapReduce能够高效地执行数据聚合、排序、过滤等操作,下面,我们将一步步探讨如何实现MapReduce来处理多个CSV文件的输入。
理解MapReduce基础
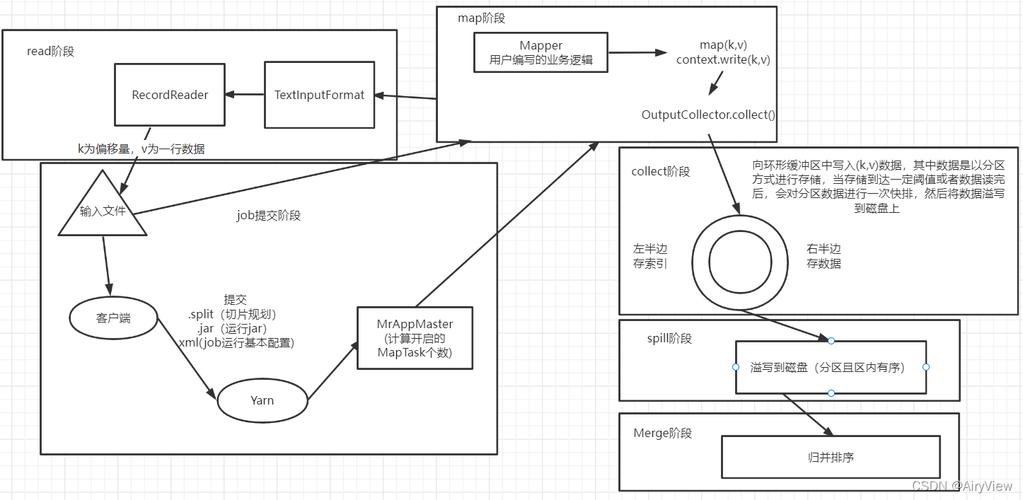
MapReduce由Google提出,其核心思想是将复杂的数据处理任务分解为两个简单的函数:Map(映射)和Reduce(归约),Map函数处理输入数据,生成中间键值对;Reduce函数则对中间键值对进行合并处理,输出最终结果。
准备CSV文件
确保你的CSV文件格式统一,即字段分隔符、数据格式等保持一致,这有助于在Map阶段简化数据处理逻辑,你可以有多个销售数据的CSV文件,每个文件包含日期、产品ID、销售量等字段。
编写MapReduce程序
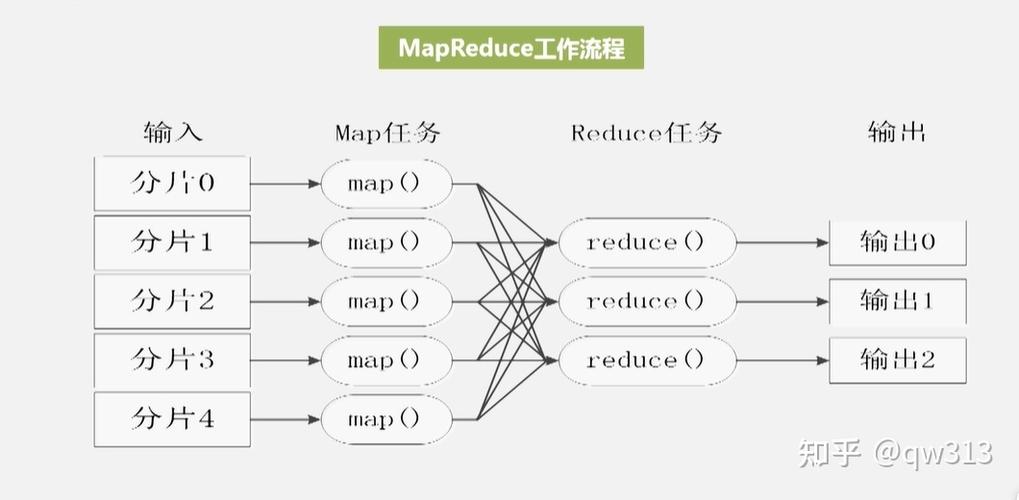
1、Map阶段:
输入:Map函数的输入通常是CSV文件的一行或多行数据。
处理:在Map阶段,你需要解析CSV行,将其转换为适合处理的格式(如键值对),可以将产品ID作为键,销售量作为值。
输出:Map函数输出中间键值对,这些键值对随后会被发送到Reduce阶段。
2、Reduce阶段:
输入:Reduce函数接收来自多个Map任务的中间键值对,这些键值对按键分组。
处理:在Reduce阶段,你需要对同一键的所有值进行合并处理,对于销售数据,你可能需要计算每个产品的总销售量。
输出:Reduce函数输出最终结果,可以是汇总后的数据,也可以是其他形式的处理结果。
配置Hadoop环境

由于MapReduce通常运行在Hadoop集群上,因此你需要配置Hadoop环境,这包括安装Hadoop、配置HDFS(Hadoop分布式文件系统)以及设置MapReduce作业的运行参数。
运行MapReduce作业
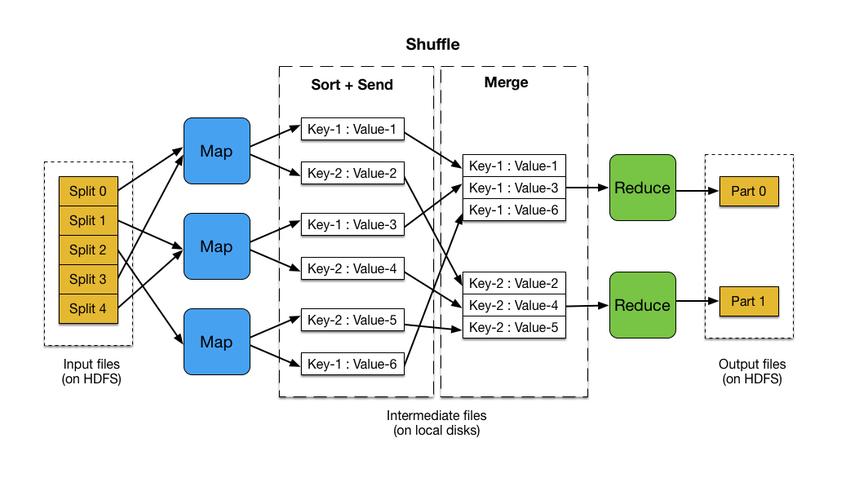
- 使用Hadoop命令行工具或编程接口(如Hadoop Streaming、Java API)提交MapReduce作业。
- 指定输入目录(包含多个CSV文件的HDFS路径)和输出目录。
- 监控作业执行状态,并在完成后检查输出结果。
优化与调试
优化:根据作业执行情况和资源使用情况,调整Map和Reduce任务的数量、内存分配等参数。
调试:利用Hadoop的日志系统定位问题,检查Map和Reduce函数的逻辑是否正确。
解答问题

问:如何实现MapReduce处理多个CSV文件的输入?
答:实现MapReduce处理多个CSV文件的输入,关键在于正确配置Hadoop环境,编写能够处理CSV数据的Map和Reduce函数,并通过Hadoop命令行或编程接口提交作业,在Map阶段,你需要解析CSV文件,将每行数据转换为键值对;在Reduce阶段,则根据键对值进行合并处理,还需要注意输入目录的设置,确保Hadoop能够正确读取所有CSV文件,通过调整Hadoop作业的配置参数,可以进一步优化作业的执行效率和资源利用率。
以上就是茶猫云对【如何实现MapReduce处理多个CSV文件的输入?】和【MapReduce处理多个CSV文件,从入门到实践】的相关解答,希望对你有所帮助,如未全面解答,请联系我们!
评论已关闭