


优化MapReduce作业中的Join操作,性能提升的关键策略包括:1) 预处理数据以减少输入数据量,如过滤无关数据;2) 选择合适的Join类型,如Map Side Join减少网络传输;3) 优化数据分区,确保相关数据在同一节点处理,减少跨节点数据传输;4) 利用索引或排序减少Join时的比较次数;5) 调整MapReduce作业的并行度,增加Map和Reduce任务数量以利用更多资源;6) 监控并分析作业执行过程,识别瓶颈并针对性优化。这些策略能有效提升MapReduce作业中Join操作的性能。
醍醐灌顶之如何优化MapReduce作业中的Join操作以提升性能?
在大数据处理领域,MapReduce作为一种广泛使用的并行编程模型,其性能优化一直是数据工程师和科学家关注的焦点,特别是在执行复杂的Join操作时,如何有效减少资源消耗、缩短处理时间,成为提升整体作业性能的关键,本文将深入探讨几种优化MapReduce作业中Join操作的策略,帮助读者理解并实践这些技术。
选择合适的Join类型
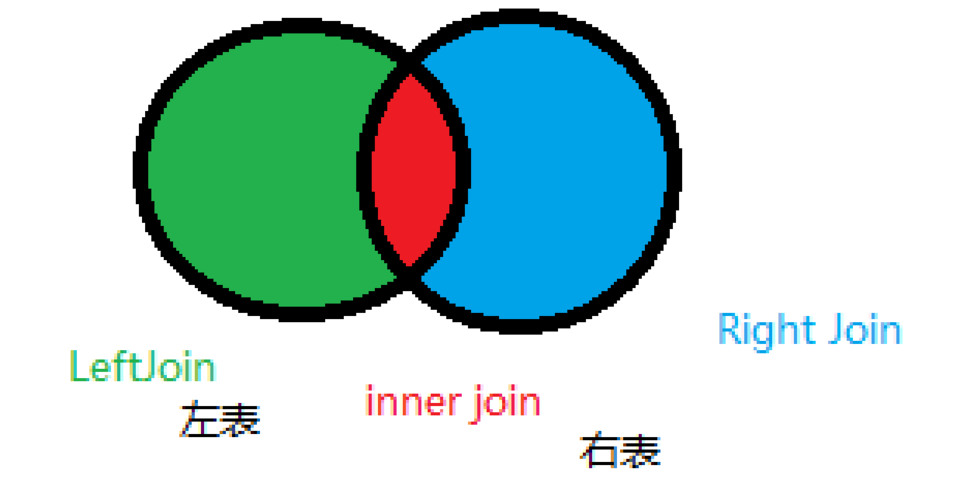
MapReduce中的Join操作主要分为Map Side Join、Reduce Side Join和Semi-Join等几种类型,每种类型都有其适用场景和优缺点:
1、Map Side Join:适用于一个数据集非常大,而另一个数据集相对较小,可以放入内存的情况,通过将小数据集**到每个Map Task的内存中(如使用Hash Table),Map Task在处理大数据集时可以直接在内存中查找匹配项,从而避免大量的数据传输和Reduce阶段的复杂处理。
2、Reduce Side Join:当两个数据集都很大,无法直接在Map阶段完成Join时,需要采用Reduce Side Join,这种方法在Map阶段将数据按Join Key分区,并在Reduce阶段进行笛卡尔积操作,这种方法在Shuffle阶段会产生大量的数据传输,可能导致性能瓶颈。
3、Semi-Join:也称为半连接,主要用于减少Reduce Side Join中的数据传输量,通过预先筛选出可能参与Join的Key,减少不必要的数据传输,从而优化性能。
优化数据分区和排序
1、合理分区:在Map阶段,通过自定义Partitioner,将具有相同Join Key的数据发送到同一个Reducer,可以减少跨Reducer的数据传输,根据数据的分布特性,动态调整分区策略,可以进一步提高性能。
2、排序和合并:在Reduce阶段之前,对Map输出的数据进行排序和合并,可以减少Reduce阶段的数据处理量,特别是当使用SortMerge Join时,排序后的数据可以更容易地进行合并操作,提高Join效率。
减少数据传输量
1、数据压缩:在数据传输过程中,使用高效的压缩算法对Map输出进行压缩,可以显著减少网络传输的数据量,从而加快数据传输速度。
2、过滤无用数据:在Map阶段,通过增加过滤逻辑,提前剔除那些不可能参与Join的数据,可以减少后续阶段的数据处理量,在Semi-Join中,通过预先筛选出可能参与Join的Key,减少不必要的数据传输。
利用内存和缓存

1、内存优化:在Map和Reduce阶段,尽量利用内存来存储中间结果和临时数据,减少磁盘I/O操作,特别是在Map Side Join中,将小数据集完全加载到内存中,可以显著提高Join操作的效率。
2、缓存机制:利用Hadoop的缓存机制(如DistributedCache),将频繁访问的小数据集缓存到各个节点的内存中,减少数据读取的延迟和开销。
使用高级技术和工具

1、Bloom Filter:在处理大规模数据集时,可以使用Bloom Filter来过滤掉那些不可能参与Join的Key,虽然Bloom Filter存在误判率,但它可以大大减少需要传输和处理的数据量。
2、Hive和Spark SQL:对于复杂的Join操作,可以考虑使用Hive或Spark SQL等高级数据处理工具,这些工具提供了更丰富的优化选项和更高效的执行计划,可以自动优化Join操作的性能。
问答环节
问题:在MapReduce作业中,如何判断应该选择Map Side Join还是Reduce Side Join?
回答:选择Map Side Join还是Reduce Side Join主要取决于两个数据集的大小和内存资源的可用性,如果其中一个数据集非常小,可以放入内存,那么选择Map Side Join通常更为高效,因为这样可以避免Reduce阶段的复杂处理和大量的数据传输,相反,如果两个数据集都很大,无法放入内存,那么就需要采用Reduce Side Join,需要注意的是,Reduce Side Join在Shuffle阶段会产生大量的数据传输,可能导致性能瓶颈,在选择Join类型时,需要综合考虑数据集的大小、内存资源的限制以及作业的性能要求。
以上就是茶猫云对【如何优化MapReduce作业中的Join操作以提升性能?】和【优化MapReduce作业中的Join操作,性能提升的关键策略】的相关解答,希望对你有所帮助,如未全面解答,请联系我们!
评论已关闭