


Python中的GET函数,作为处理HTTP请求的重要工具,是轻松获取网络资源的利器。通过内置的requests库或urllib模块,开发者可以简单地使用GET方法向服务器发送请求,并获取返回的数据,如网页内容、API接口数据等。这种方法广泛应用于网络爬虫、数据抓取、Web服务交互等场景,极大地简化了网络资源的获取过程。
在Python编程的世界里,网络请求是不可或缺的一部分,无论是从API获取数据、爬取网页内容还是与远程服务器交互,都离不开网络请求,而GET请求作为HTTP协议中最常用的方法之一,被广泛应用于各种场景,Python中,实现GET请求的方式多种多样,但最常用且易于上手的莫过于使用requests库中的get函数,下面,我们就来详细了解一下Python中get函数的用法。
安装requests库
确保你的Python环境中已经安装了requests库,如果还没有安装,可以通过pip命令轻松安装:
pip install requests
使用requests.get函数
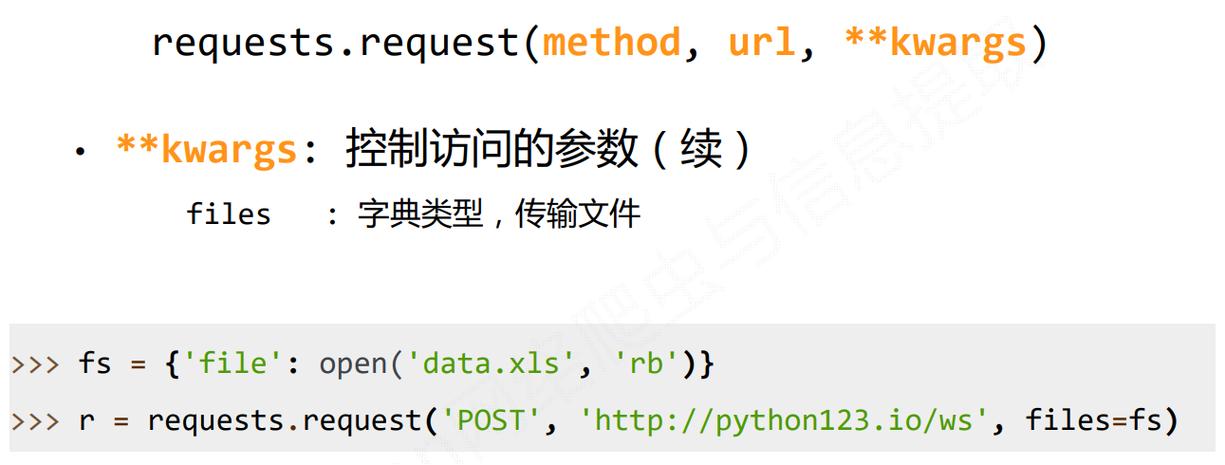
requests.get函数是requests库中用于发起GET请求的函数,其基本语法如下:

import requests response = requests.get(url, params=None, **kwargs)
url:你想要请求的URL地址。
params:可选参数,用于向URL添加查询参数,它是一个字典或字节序列,如果是字典,则会被自动编码为URL的一部分。
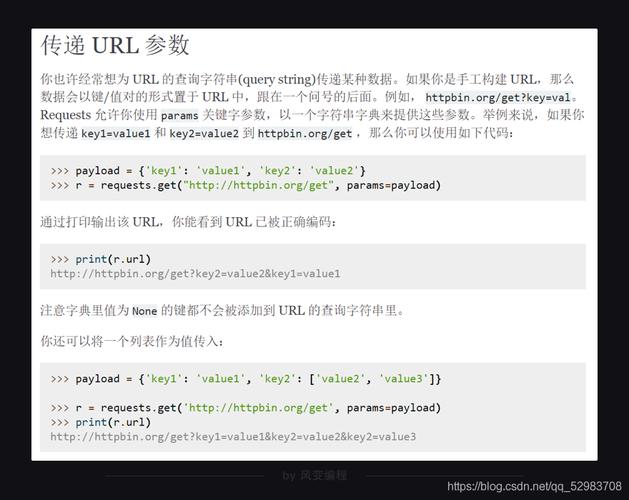
**kwargs:其他可选参数,如headers(请求头)、timeout(超时时间)等。
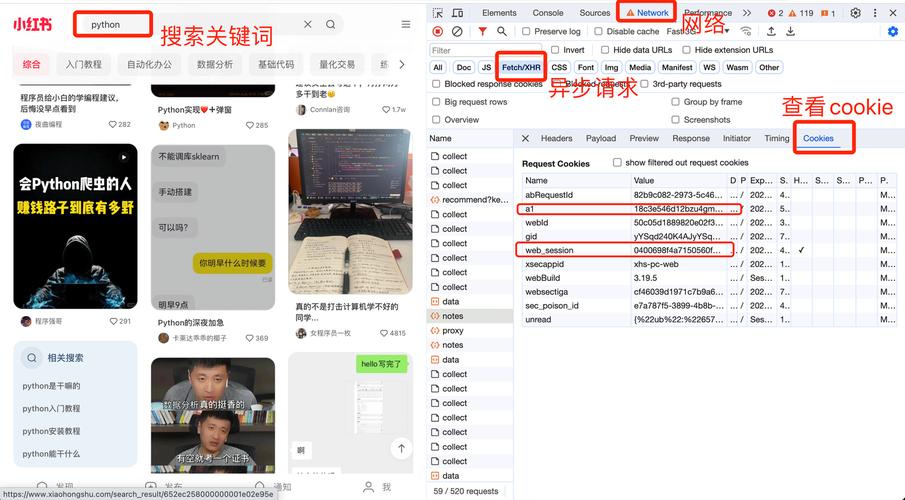
示例

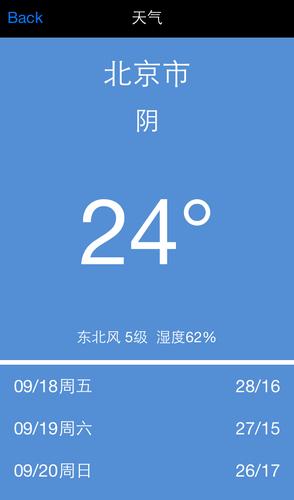
假设我们想要从某个API获取天气信息,该API的URL为https://api.example.com/weather,并且我们需要通过查询参数city来指定城市。
import requests
定义URL和查询参数
url = 'https://api.example.com/weather'
params = {'city': 'Beijing'}
发起GET请求
response = requests.get(url, params=params)
检查请求是否成功
if response.status_code == 200:
# 读取响应内容(假设返回的是JSON格式)
weather_data = response.json()
print(weather_data)
else:
print('请求失败,状态码:', response.status_code)常见问题解答

Q1: 如何处理GET请求中的超时问题?
A: 在使用requests.get时,可以通过timeout参数来设置请求的超时时间(以秒为单位),如果请求在指定时间内没有完成,将会抛出一个requests.exceptions.Timeout异常。
try:
response = requests.get(url, timeout=5) # 设置超时时间为5秒
# 处理响应
except requests.exceptions.Timeout:
print('请求超时')Q2: 如何添加自定义的请求头?
A: 通过headers参数可以添加自定义的请求头。headers应该是一个字典,其中键是请求头的名称,值是对应的值。
headers = {
'User-Agent': 'My Custom User-Agent',
'Authorization': 'Bearer YOUR_ACCESS_TOKEN'
}
response = requests.get(url, headers=headers)Q3: 如何处理GET请求中的重定向?
A:requests库默认会处理HTTP重定向,如果你想要禁用重定向,可以将allow_redirects参数设置为False。
response = requests.get(url, allow_redirects=False)
这样,如果服务器返回了一个重定向响应(如301或302状态码),requests将不会跟随重定向,而是直接返回该响应。
通过上面的介绍和示例,相信你已经对Python中requests.get函数的用法有了较为全面的了解,无论是进行简单的API调用,还是复杂的网络爬虫开发,requests.get都是你的得力助手。

评论已关闭