


《Oracle数据库全角半角字符转换实战指南》概述了如何在Oracle数据库环境中高效处理全角与半角字符之间的转换。指南详细讲解了全角字符(如中文标点、日文字符等)与半角字符(如英文标点)的区别,并提供了实用的SQL语句和函数示例,帮助用户实现自动或手动转换,以满足数据清洗、国际化支持等需求。通过遵循本指南,数据库管理员和开发人员能够轻松应对字符编码问题,确保数据的一致性和准确性。
在数据库管理和数据处理过程中,经常会遇到字符编码不一致的问题,尤其是涉及到中日韩等使用双字节字符集(如GBK、UTF-8)的语言环境时,全角字符(如全角空格、全角标点符号等)和半角字符的转换显得尤为重要,Oracle数据库作为业界领先的数据库管理系统,提供了丰富的函数和工具来处理这类字符编码问题,本文将详细介绍在Oracle数据库中如何实现全角字符与半角字符之间的转换,帮助读者解决实际应用中的编码难题。
全角与半角字符的基本概念
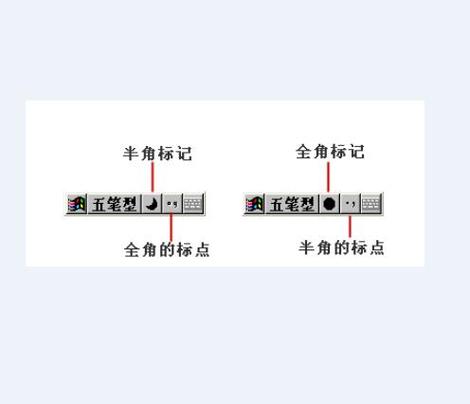
全角字符:在中文输入法中,标点符号等字符占用两个标准字符位置,称为全角字符,全角字符主要用于中文排版,以保持与汉字相同的视觉宽度。
半角字符:与之相对,半角字符占用一个标准字符位置,常见于英文和数字的输入。
Oracle数据库中的字符处理函数
Oracle数据库提供了多种字符处理函数,其中REPLACE、TRANSLATE等函数在字符转换中尤为常用,直接的全角到半角或反之的转换并不直接支持,需要通过一些技巧或自定义函数来实现。
实现全角到半角的转换
由于Oracle没有内置的直接函数来转换全角到半角,我们可以采用TRANSLATE函数结合字符映射表的方式来实现,但这种方法需要手动定义全角到半角的映射关系,对于大量字符来说较为繁琐。
一个更实用的方法是使用PL/SQL编写自定义函数,通过字符的Unicode编码范围来判断并转换,全角空格的Unicode编码是U+3000,而半角空格是U+0020,通过遍历字符串中的每个字符,检查其Unicode编码,并替换为对应的半角字符。
CREATE OR REPLACE FUNCTION full_to_half_char(p_str IN VARCHAR2)
RETURN VARCHAR2 IS
l_result VARCHAR2(4000);
l_char CHAR(1);
l_unicode NUMBER;
BEGIN
l_result := '';
FOR i IN 1 .. LENGTH(p_str) LOOP
l_char := SUBSTR(p_str, i, 1);
l_unicode := UNISTR(l_char);
-- 示例:转换全角空格到半角空格
IF l_unicode = UNISTR('\3000') THEN
l_result := l_result || CHR(160); -- 半角空格的ASCII码是160,但这里用CHR(32)即' '更常见
ELSE
l_result := l_result || l_char;
END IF;
-- 这里可以添加更多全角到半角的转换逻辑
END LOOP;
RETURN l_result;
END full_to_half_char;
/注意:上述示例中,全角空格到半角空格的转换使用了ASCII码160作为示例(实际上半角空格常用ASCII码32,即' '),具体转换逻辑需根据实际需求调整。
实现半角到全角的转换
半角到全角的转换逻辑与上述类似,也是通过检查字符的Unicode编码,并替换为对应的全角字符,由于全角字符集相对固定,可以预先定义好映射表,然后在函数中查找替换。
常见问题解答

问题1:Oracle数据库中没有直接的全角半角转换函数,如何高效处理大量数据的转换?
答:对于大量数据的转换,建议采用PL/SQL编写自定义函数,并在数据库层面进行处理,这样可以利用Oracle数据库的优化器来优化查询和转换过程,考虑将转换逻辑封装成存储过程或函数,以便在多个地方重用。
问题2:在Oracle中,如何检查一个字符串是否包含全角字符?
答:可以通过编写一个PL/SQL函数,遍历字符串中的每个字符,检查其Unicode编码是否落在全角字符的编码范围内(如U+FF01至U+FF5E为全角标点符号),如果发现任何全角字符,则返回TRUE,否则返回FALSE。
问题3:Oracle数据库中的字符编码设置对全角半角转换有何影响?
答:Oracle数据库的字符编码设置(如NLS_CHARACTERSET)直接影响到数据库中存储的字符数据的编码方式,如果数据库使用的字符集不支持全角字符(如US7ASCII),则无法直接存储全角字符,在进行全角半角转换时,需要确保数据库使用的字符集能够支持目标字符集(如

相关文章
评论已关闭