


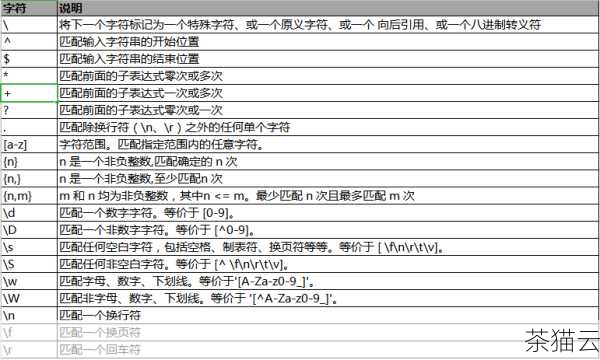
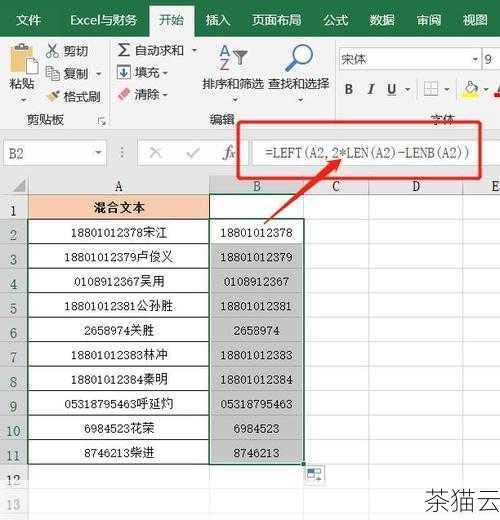
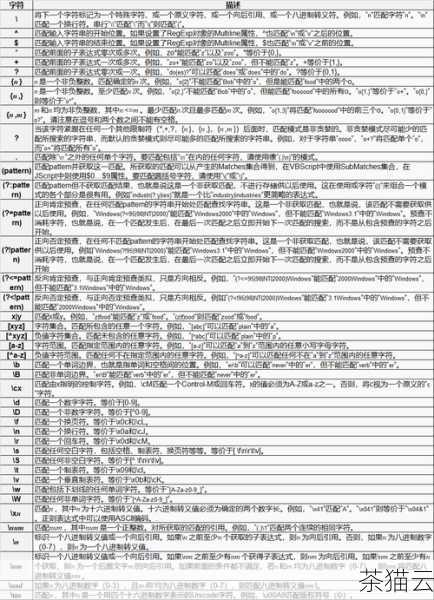
在编程的世界里,Python 正则表达式就像是一把神奇的钥匙,能够帮助我们轻松地打开复杂文本处理的大门,它赋予了开发者强大的能力,使我们能够从大量的文本数据中快速准确地提取出所需的信息,进行有效的模式匹配和文本操作。

正则表达式,是一种用于描述和匹配文本模式的工具,它由一系列特殊的字符和元字符组成,这些字符和元字符具有特定的含义和功能,通过巧妙地组合这些字符,我们可以创建出各种复杂的模式,以满足不同的文本处理需求。
在 Python 中,使用正则表达式主要通过re 模块来实现,我们需要导入这个模块:
import re
让我们来看一些常见的正则表达式操作。

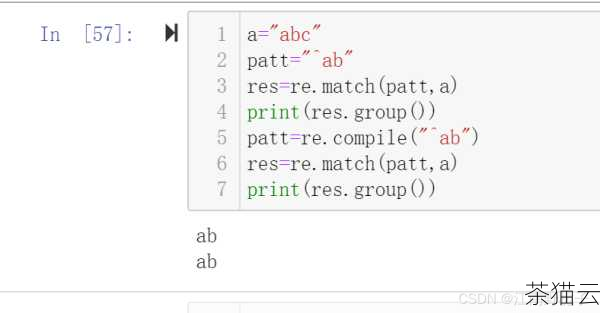
我们想要查找一个字符串中是否包含特定的子字符串,假设我们要检查一个文本是否包含 "hello" 这个单词,我们可以这样写:
text = "Hello, World!"
match = re.search("hello", text, re.IGNORECASE)
if match:
print("找到匹配项")
else:
print("未找到匹配项")在上述代码中,re.search() 函数用于在字符串中搜索匹配的模式。re.IGNORECASE 表示忽略大小写。
再比如,我们想要提取出文本中的所有数字,可以这样做:
text = "There are 10 apples and 5 oranges" numbers = re.findall(r'\d+', text) print(numbers)
这里的r'\d+' 是一个正则表达式模式,\d 表示数字,+ 表示匹配前面的字符一次或多次。

正则表达式还可以用于替换文本中的某些部分,将文本中的所有数字替换为 "NUMBER":

text = "There are 10 apples and 5 oranges" new_text = re.sub(r'\d+', 'NUMBER', text) print(new_text)
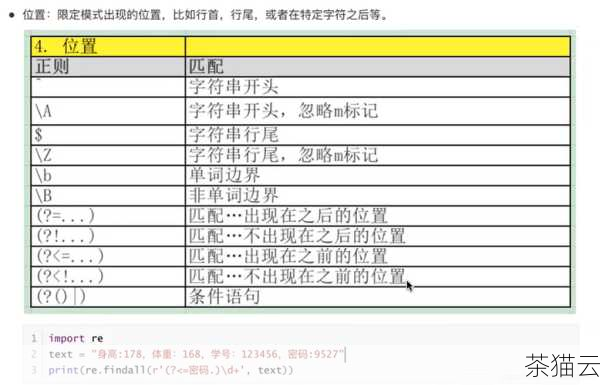
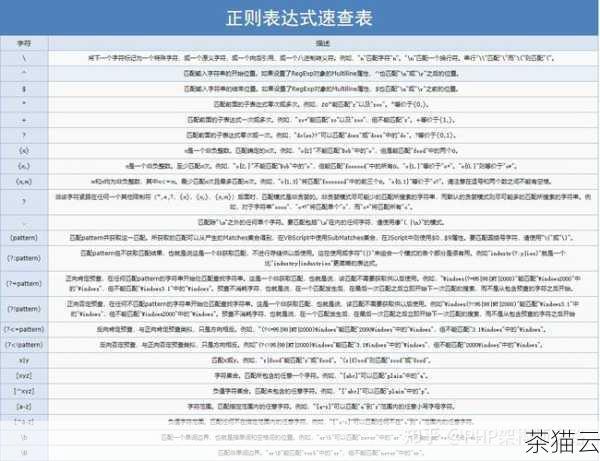
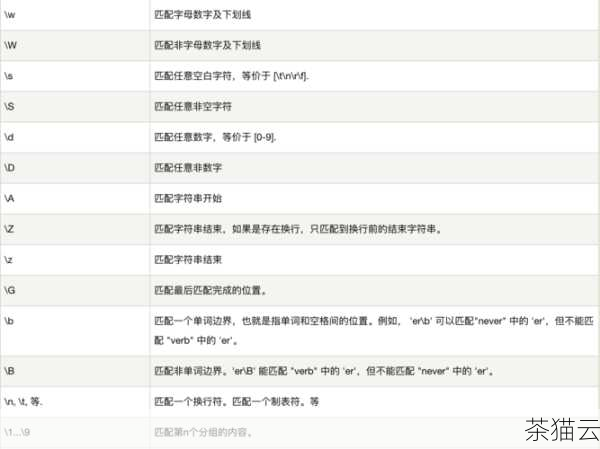
除了上述基本操作,正则表达式还有许多高级用法,如分组、前向断言、后向断言等,这些可以帮助我们处理更加复杂的文本模式。
Python 正则表达式是一项非常强大且实用的技术,无论是在数据清洗、文本分析、网络爬虫还是其他涉及文本处理的领域,都能发挥巨大的作用,只要我们熟练掌握它,就能大大提高我们的编程效率和处理文本的能力。

回答几个与 Python 正则表达式相关的问题:
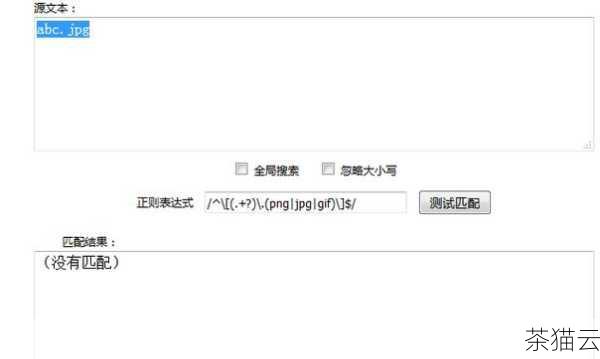
问题一:如何使用正则表达式匹配电子邮件地址?

答:以下是一个简单的正则表达式模式来匹配常见的电子邮件地址:
r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$'
这个模式首先匹配一个或多个字母、数字、点、下划线、加号或减号,然后是@ 符号,接着是一个或多个字母、数字或连字符,再接着是一个点,最后是一个或多个字母、数字、点、连字符,但请注意,这并不是一个完美的电子邮件地址验证模式,因为电子邮件地址的规则非常复杂,但对于大多数常见的情况是有效的。

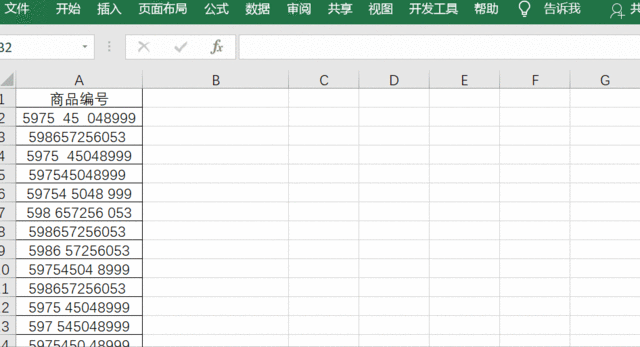
问题二:怎样用正则表达式匹配手机号码?

答:常见的手机号码正则表达式模式可以是这样:
r'^1[3-9]\d{9}$'这个模式以数字 1 开头,第二位是 3 到 9 中的一个数字,然后是 9 个 0 到 9 的数字,但需要注意,手机号码的规则可能会随着时间和地区而有所变化。

问题三:如何使用正则表达式去除文本中的所有空格?
答:可以使用以下正则表达式模式和re.sub() 函数来实现:
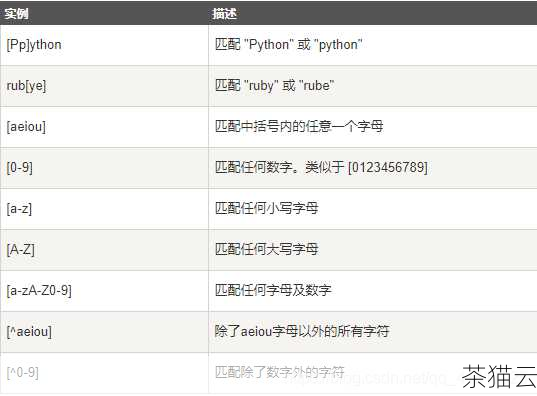
text = " Hello World " new_text = re.sub(r'\s+', '', text) print(new_text)
这里的\s 表示空格、制表符等空白字符,+ 表示匹配一个或多个。

评论已关闭