


在数据分析和处理的领域中,Pandas 是一个强大而广泛使用的 Python 库,模糊匹配功能为我们在处理数据时提供了极大的灵活性和便利性。

模糊匹配,顾名思义,并非是精确的一一对应匹配,而是在一定程度上允许相似性和不确定性,这在现实的数据处理场景中非常常见,因为数据往往并不总是完美、准确和整齐的。
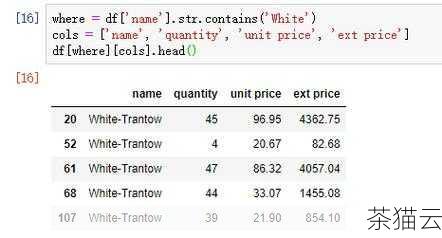
在 Pandas 中,实现模糊匹配主要依靠一些特定的方法和函数。str.contains() 方法就是一个常用的工具,它可以检查某个列中的值是否包含指定的字符串模式,通过这个方法,我们可以轻松地筛选出符合模糊条件的数据行。
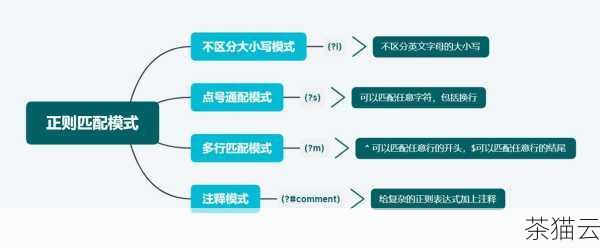
str.match() 方法则用于判断字符串是否匹配给定的正则表达式模式,正则表达式为我们提供了更强大、更精细的模式定义能力,使我们能够处理各种复杂的模糊匹配需求。
在实际应用中,模糊匹配可以帮助我们解决很多问题,当我们需要从大量的文本数据中找出包含特定关键词的记录时,模糊匹配就能发挥巨大作用,又或者,在处理用户输入的不精确搜索条件时,通过模糊匹配可以提供更友好和实用的搜索结果。
为了更好地理解和运用 Pandas 的模糊匹配,让我们来看一些具体的示例,假设我们有一个包含产品名称和描述的数据集,我们想要找出所有包含“手机”这个关键词的产品记录,我们可以这样写代码:
import pandas as pd
data = {'Product': ['智能手机', '老年手机', '平板电脑', '智能手表'],
'Description': ['高性能的智能手机', '适合老年人使用的手机', '功能强大的平板电脑', '时尚的智能手表']}
df = pd.DataFrame(data)
filtered_df = df[df['Product'].str.contains('手机')]
print(filtered_df)再比如,如果我们想要找出产品名称以“智能”开头的记录,就可以使用str.startswith() 方法:

filtered_df = df[df['Product'].str.startswith('智能')]
print(filtered_df)在使用模糊匹配时,还需要注意一些性能方面的问题,如果数据量非常大,不当的模糊匹配操作可能会导致性能下降,在实际应用中,需要根据数据的特点和需求,合理选择匹配方法和优化匹配逻辑。
回答几个与 Pandas 模糊匹配相关的问题:
问题一:如何在模糊匹配中处理大小写不敏感的情况?
答:可以通过在相关方法中设置参数来实现大小写不敏感的模糊匹配,在str.contains() 方法中,可以添加case=False 参数,使其在匹配时不区分大小写。

问题二:怎样使用正则表达式进行更复杂的模糊匹配?
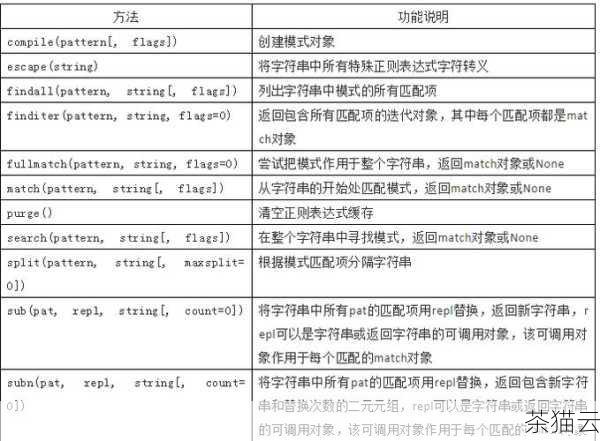
答:首先需要了解正则表达式的基本语法和规则,然后将正则表达式模式作为参数传递给str.match() 等相关方法,要匹配包含数字的字符串,可以使用\d 这个正则表达式元字符。

问题三:模糊匹配结果不准确该如何调试和优化?

答:可以先检查匹配模式是否正确,是否过于宽泛或过于严格,可以逐步缩小或扩大匹配范围进行测试,观察结果的变化,也可以考虑对数据进行预处理,比如清理噪声、转换数据格式等,以提高匹配的准确性。

评论已关闭