


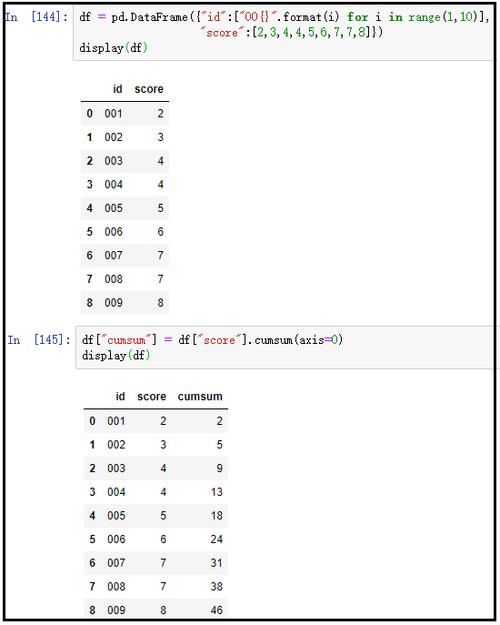
Python中的cumsum函数是数据处理中的强大工具,能够轻松实现数据的累加操作。无论是使用NumPy库还是Pandas库,cumsum都能快速对数组或序列中的元素进行累积求和,生成一个新的数组或序列,其中每个位置的值都是原数组中该位置及其之前所有位置值的和。这一功能在数据分析、时间序列处理及金融数据分析等领域尤为实用,是Python数据科学工具箱中的一大神器。
在Python的数据处理与分析领域,Pandas库以其强大的数据处理能力深受欢迎,而在Pandas的众多函数中,cumsum()函数无疑是一个既实用又高效的工具,它能够帮助我们轻松实现数据的累加操作,无论是财务分析中的累计收益计算,还是时间序列分析中的累计总和统计,cumsum()函数都能大显身手。
cumsum函数的基本用法

cumsum()函数是Pandas库中Series和DataFrame对象的一个方法,用于计算数据的累加和,当你对一个Series或DataFrame的某一列(或整个对象)调用cumsum()方法时,它会返回一个新的Series或DataFrame,其中包含了从起始点到当前位置的所有元素的累加和。

示例代码:
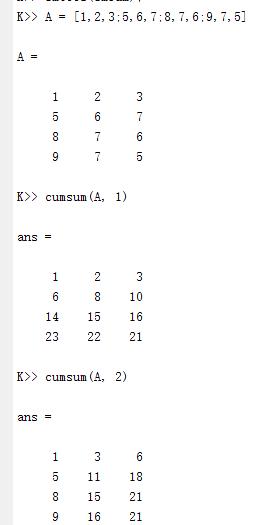
import pandas as pd 创建一个简单的Series data = pd.Series([1, 2, 3, 4, 5]) 使用cumsum()计算累加和 cumulative_sum = data.cumsum() print(cumulative_sum) 输出: 0 1 1 3 2 6 3 10 4 15 dtype: int64
在这个例子中,cumsum()函数计算了data Series中每个元素的累加和,并将结果存储在cumulative_sum Series中。
cumsum函数的高级应用

除了基本的累加操作外,cumsum()函数还可以结合Pandas的其他功能,实现更复杂的数据处理任务,你可以使用条件筛选后的数据进行累加,或者结合groupby函数对分组后的数据进行累加操作。
分组累加示例:
创建一个包含分类和数值的DataFrame
df = pd.DataFrame({
'Category': ['A', 'A', 'B', 'B', 'A'],
'Value': [1, 2, 3, 4, 5]
})
对每个分类的Value列进行累加
cumulative_sum_by_category = df.groupby('Category')['Value'].cumsum()
print(cumulative_sum_by_category)
输出:
0 1
1 3
2 3
3 7
4 8
Name: Value, dtype: int64在这个例子中,我们首先根据Category列对DataFrame进行了分组,然后对每个分组内的Value列应用了cumsum()函数,实现了分组累加的效果。
cumsum函数相关问题解答
问题1:cumsum()函数是否支持对DataFrame的多列同时应用累加操作?
答:cumsum()函数默认是对DataFrame的每一列分别进行累加操作,如果你想要对多列同时应用累加操作,可以直接在DataFrame上调用cumsum()方法,而不需要指定列名,这样,DataFrame中的每一列都会独立地进行累加操作。
问题2:如何对满足特定条件的行进行累加操作?

答:如果你想要对满足特定条件的行进行累加操作,可以先使用条件筛选(如df[df['Column'] > value])来选取满足条件的行,然后再对这些行应用cumsum()函数,不过,需要注意的是,直接筛选后的结果可能是一个新的DataFrame或Series,你需要在这个结果上调用cumsum()。
![答:如果你想要对满足特定条件的行进行累加操作,可以先使用条件筛选(如df[df['Column'] > value])来选取满足条件的行,然后再对这些行应用cumsum()函数,不过,需要注意的是,直接筛选后的结果可能是一个新的DataFrame或Series,你需要在这个结果上调用cumsum()。](https://vps.cmy.cn/zb_users/upload/2024/08/20240803024320172262420013862.jpeg)
问题3:cumsum()函数在处理大数据集时性能如何?
答:Pandas的cumsum()函数在处理大数据集时通常表现出色,因为它是在底层使用高效的C语言编写的,性能还是会受到数据大小、系统资源以及Pandas版本等因素的影响,如果处理的数据集非常大,建议考虑使用更高效的数据处理工具或方法,如Dask等分布式计算框架,或者优化数据加载和处理的逻辑。

评论已关闭